PDF 翻译卡住不动,或者翻译完发现有几页漏译,是很多用户第一次处理外文 PDF 时会遇到的问题。尤其是扫描版 PDF、图片型 PDF、页数很多的论文、合同附件、产品手册和带大量图片的说明书,更容易出现等待时间长、部分页面没识别、表格内容缺失的情况。
这类问题不一定是翻译工具“坏了”。多数时候,真正原因在文件结构:页面太大、图片层太多、OCR 识别不完整、PDF 加密、网络中断,或者原文件本身就不是可编辑文本。处理思路也不是重复上传,而是先判断文件类型,再按原因拆解。
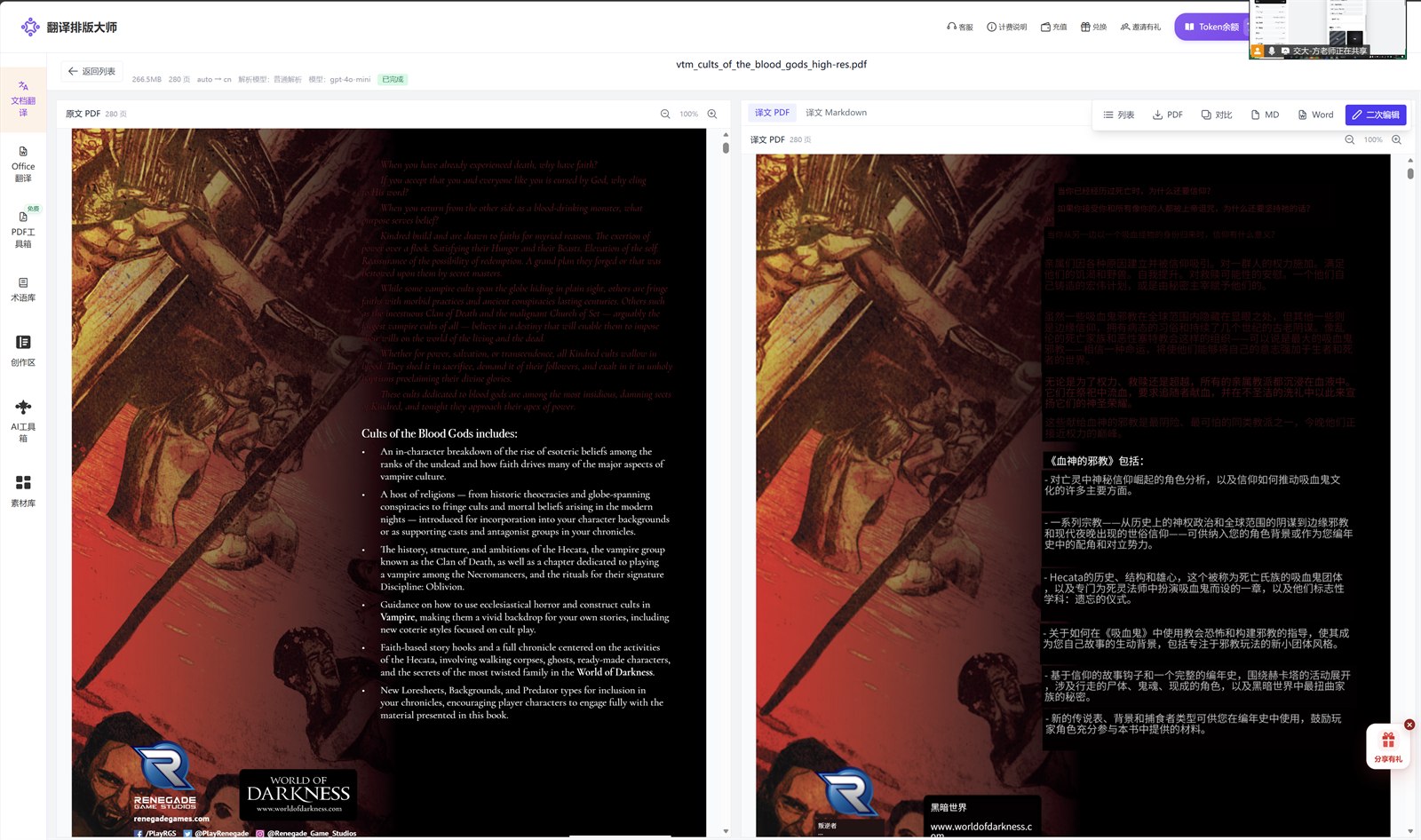
先判断:是卡住,还是正在处理?
PDF 翻译比普通网页翻译慢,原因是它不只翻译文字,还要处理页面结构、图片、表格、页眉页脚和导出格式。几十页的文字型 PDF,通常比几页扫描件更容易处理;一份 20 页高清扫描合同,反而可能比 100 页文字型文档更慢。
可以先看三个信号:
- 文件是否很大,比如超过几十 MB。
- 页面是否都是图片,无法选中文字。
- 是否包含大量表格、截图、印章、公式、双栏或水印。
如果这些情况都存在,等待时间变长是正常的。但如果长时间没有任何进度、刷新后仍停在同一步,才需要按下面的步骤排查。
常见原因一:文件太大或页数太多
大文件最容易出现上传慢、识别慢、翻译慢和导出慢。很多 PDF 看起来只有几十页,但每页都是高清扫描图,实际处理量会很大。
建议先这样处理:
- 先用 3 到 5 页测试,不要一开始上传整本资料。
- 删除空白页、重复页、封底和不需要翻译的附件页。
- 如果文件超过几十 MB,先压缩图片或拆分成几段。
- 优先处理正文页,再处理封面、目录和附录。
如果只是想了解全文大意,可以先做 PDF全文翻译;如果要保持页面结构,再继续检查 PDF翻译保留排版。
常见原因二:扫描版 PDF 没有文字层
扫描版 PDF 的页面本质上是图片。翻译前必须先 OCR 识别文字,如果图片模糊、倾斜、反光、有阴影,OCR 就可能漏字、错字,甚至整段识别失败。
遇到扫描件漏译,优先检查这些位置:
- 标题和小标题有没有识别出来。
- 表格里的数字、型号、单位有没有缺失。
- 页眉页脚、图注、脚注有没有被忽略。
- 印章、签名、手写批注是否被误识别。
- 双栏或多栏页面的阅读顺序是否错乱。
这类文件建议先看 扫描版PDF翻译OCR流程,先解决识别质量,再谈翻译和排版。不要把扫描件当成普通文字 PDF 直接处理。
常见原因三:图片层、表格和公式太复杂
产品说明书、检测报告、论文和报价单里经常有表格、公式、流程图、截图标注。翻译工具需要判断哪些是文字、哪些是图片、哪些要保留原样,这一步比纯文本翻译复杂得多。
这些内容最容易漏:
- 图片里的小字和标注。
- 表格边角处的单位、备注和脚注。
- 公式周围的说明文字。
- 页眉页脚里的文档编号和版本号。
- 多栏论文中跨栏的段落。
如果翻译后版面也乱了,可以继续看 PDF翻译后排版乱怎么办,先把漏译和错译找出来,再处理格式。
常见原因四:PDF 有权限限制或异常结构
有些 PDF 可以打开,但不能复制、不能编辑、不能提取文本。这类文件可能设置了权限限制,或者由特殊软件生成,内部结构不标准。
可以先试这几件事:
- 打开 PDF 后尝试复制一段文字。
- 检查文件是否要求密码。
- 换一个 PDF 阅读器打开,看是否能正常显示。
- 另存为一份新 PDF 后再上传。
- 如果只有少数页异常,先把异常页单独导出测试。
如果文件来自客户、供应商或旧系统,异常结构并不少见。不要只看“能打开”,还要看是否能正常选中文字和提取内容。
常见原因五:网络中断或重复提交
在线处理 PDF 时,上传、识别、翻译、排版和导出都依赖稳定连接。网络中断后,页面可能看起来停住,但后台任务未必失败。
建议这样处理:
- 不要连续点击提交同一个大文件。
- 等待一段时间后刷新任务列表或结果页。
- 如果任务没有生成,换小文件测试。
- 如果小文件正常,大概率是原 PDF 太大或结构复杂。
- 如果所有文件都异常,再判断是否是网络或服务问题。
PDF 翻译漏译后怎么检查?
漏译不一定一眼能看出来,尤其是合同、报价单、论文和说明书。建议按页面类型检查,而不是从头到尾随便翻。
重点看这些区域:
- 封面、目录、章节标题。
- 表格表头、金额、单位、型号和备注。
- 图片说明、脚注、页眉页脚。
- 合同条款编号、附件编号、签章区域。
- 论文公式、图表标题、参考文献说明。
如果文件要交付给客户或同事,建议导出前至少抽查封面、目录、表格页、图文混排页和最后几页。普通正文漏译容易发现,页眉页脚和表格角落的漏译反而更容易被忽略。
一个更稳的处理流程
可以按这个顺序处理:
- 先判断文件是文字型 PDF 还是扫描版 PDF。
- 大文件先拆分,先测试 3 到 5 页。
- 扫描件先看 OCR 识别质量。
- 翻译后先查漏译,再查排版。
- 对合同、报价单、论文和说明书做重点页复核。
- 最后再导出 PDF,并打开成品确认页码、表格和图片说明。
这个流程看起来多一步,但比反复上传同一个文件更省时间。尤其是扫描版 PDF 和复杂商务文件,先定位问题比直接重试更有效。
常见问题
PDF 翻译一直处理中,是不是失败了?
不一定。大文件、扫描件和图片很多的 PDF 处理时间会更长。可以先用少量页面测试,如果小文件正常,说明主要问题在原文件大小或结构。
PDF 翻译后为什么有几页没翻?
常见原因是这些页面没有文字层、OCR 没识别出来,或者页面里文字太小、背景复杂、图片层过多。建议先检查这些页面是否能选中文字。
扫描版 PDF 漏译怎么办?
先提高 OCR 识别质量。可以换更清晰的 PDF、减少阴影和倾斜,或者把异常页面单独处理,再进入翻译流程。
大文件 PDF 应该整份上传还是拆分?
如果只是几十页文字型 PDF,可以整份处理;如果是高清扫描件、说明书或合同附件,建议先拆分测试,再分批处理。
翻译结果出来了,但格式乱怎么办?
先确认有没有漏译和错译,再处理版式。表格、图注、页眉页脚、目录和签章页要优先检查,可以参考 PDF翻译后排版乱怎么办。
小结
PDF 翻译卡住不动或漏译,通常不是单纯的翻译问题,而是文件大小、扫描质量、OCR、页面结构和网络稳定性共同影响的结果。
处理这类文件,最有效的方法是先小范围测试,再按文件类型排查。文字型 PDF 重点看排版和导出,扫描版 PDF 重点看 OCR 和漏译,大文件则先拆分、压缩、分批处理。
如果你要处理外文合同、论文、说明书或图片型 PDF,可以先从 3 到 5 页开始测试,确认识别、翻译和排版结果都正常后,再处理整份文件。